
Richard Dolewski hat 20 Katastrophen als Team Leiter für «Disaster Recovery» erlebt. Cloud-Anbieter und Magnetbänder seien genauso unbrauchbar wie das Vertrauen in Menschen. Den Informatik-Verantwortlichen am Anlass von Extendance in Zürich erklärte er die Sicherung des stabilen Geschäftsbetriebs.

Die USA treffen Katastrophen öfter als die Schweiz, wie 2012 der Wirbelsturm Sandy, doch meist gefährden menschliche Fehler die Unternehmensprozesse. (pd)
Die Nachfrage nach moderner Informatik wie Cloud Computing und Big Data erfordert mehr Rechenzentren (RZ). Doch ein RZ wirtschaftlich zu bauen und sicher zu betreiben ist höchste Ingenieurskunst, an der die grössten Namen scheitern. Microsoft, Amazon, Google und Facebook hatten alle schon Ausfälle zu entschuldigen. Die Katastrophen und Datenverluste entstanden nicht nur wegen Datendiebstahl, sondern aus selbst verschuldetem Fehlern. «Auf die Public-Cloud kann man sich nicht verlassen», sagte Richard Dolewski, Vice President Business Development von Velocity, am «3. Data Center Management Event» der Beratungsfirma Extendance. Die Veranstaltung für CIO und IT-Entscheider fand im UBS-Konferenzzentrum Grünenhof statt.
Datenverlust gefährdet Geschäftstätigkeit

Richard Dolewski hat die Selbstironie auch nach 370 Notfall-Wiederherstellungen behalten. (pd)
Auch Schweizer Anbieter wie Swisscom oder interne Informatik-Abteilungen sind nicht vor Fehlern und Naturkatastrophen gefeiht. Der Ausfall eines RZ kostet Millionen von Franken, ein Stillstand Milliarden. «Bei Ausfällen gehen immer Daten verloren. Der Verlust von besonders kritischen Daten bedeutet sogar die Geschäftsaufgabe», so Dolewski. Hier kommt «Disaster Recovery» zum Einsatz, dem Prozess für die Notfall-Wiederherstellung von IT-Systemen. Dolewski hat in den USA über 20 Katastrophen als Team Leader erlebt und in den letzten 5 Jahren über 370 «Disaster Recoverys» durchgeführt. Vor und nach den Wirbelstürmen Sandy (2012) und Irene (2011) war er fast rund um die Uhr im Einsatz. Das waren aber nicht unbedingt seine meistbeschäftigten Zeiten.

Die meisten Katastrophen für Informatik entstünden aus Fehlern von Menschen. CIO müssen sich laut Dolewski zwei Fragen stellen: Sind sie bereit für das Katastrophen-Szenario und sind sie in ihr Unternehmen integriert? Eine erfolgreiche Notfall-Wiederherstellung bedinge genaue, mit dem Unternehmen vereinbarte Punkt- und Zeit-Vorgaben: Wie lange darf ein Geschäftsprozess ausfallen und wie viel Datenverlust kann in Kauf genommen werden? (Mehr im Kasten: Disaster Recovery)
«Auf die Public-Cloud kann man sich nicht verlassen» Richard Dolewski.
Genauso radikal wie eine Naturkatastrophe ist Dolewski in seinen schützenden Massnahmen. Geschäftsprozesse solle man selbst in «Private Clouds» sicherstellen oder einem spezialisierten Partner anvertrauen. Dolewski plädiert in jedem Fall für komplett virtualisierte Systeme, weil mit dem Hypervisor dazwischen (dem trennenden Kern der Virtualisierungs-Software zwischen Hardware und Betriebssystem) jedes System gleich ist. Somit könne schneller auf Hardware-Fehler reagiert werden. Der direkte Betrieb auf echter Hardware bedeute eher Hoffen als Vertrauen. In Dolewskis englischen Muttersprache nennt man das: «Start and Pray!»
Sicherer Betrieb ohne Hardware-Ärger
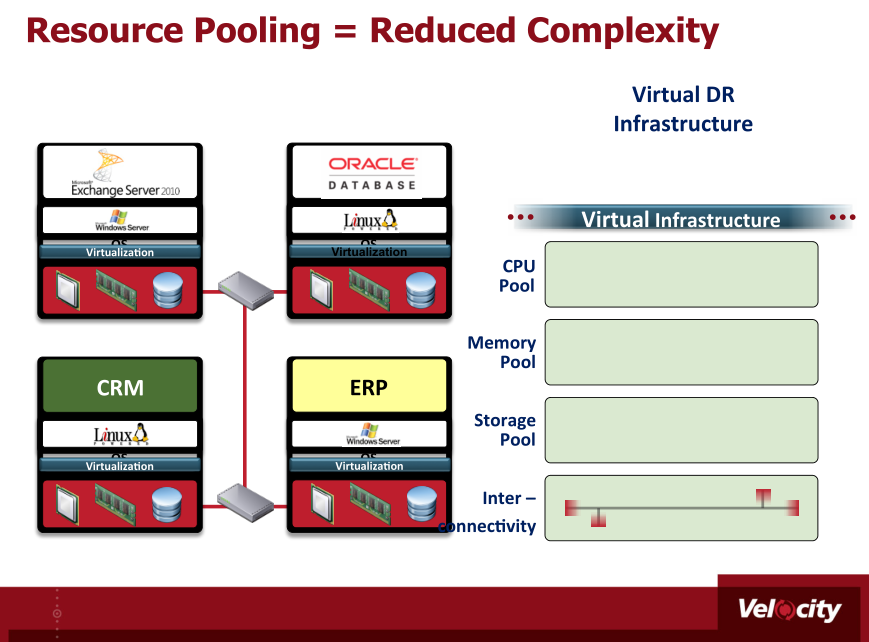
Die Ressourcen (links) stehen in einer virtuellen Infrastruktur (rechts), respektive in einer Private Cloud, dynamisch zur Verfügung von für Disaster Recovery. (Velocity)
Laut Dolewski brauche man sich heute nicht mehr mit den heterogenen Hardware-Umgebungen abzumühen: «Virtualisierung macht die Systeme flexibler, sicherer und verschiebbar.» Die Komplexität reduziert sich. Das Rechenzentrum mit virtuellen Instanzen an Stelle von identischen Hardware-Systemen für «Desaster Recovery» koste in Anschaffung und Betrieb viel weniger, weil nicht jedes System doppelt eingekauft werden muss und ständig läuft. Mit dieser «Private Cloud» lassen sich Ressourcen zusammenführen (Pooling) – das spart zusätzlich Energie und Kosten. Tägliche Backups der Systeme seien Pflicht – und zwar von allem, nicht nur von wichtigen Teilen. Nur schon die Trennung und Definition von Wichtig und Unwichtig verschlinge unnötig Zeit und könne jederzeit ändern. Auch alle Informationen, um die laufenden Systeme und Prozesse zu verstehen, müssen automatisiert gespeichert werden.
Wie lange darf ein Geschäftsprozess ausfallen und wie viel Datenverlust kann in Kauf genommen werden? Richard Dolewski
«Die Menschen sind das Problem», sagte Dolewski, zu oft seien sie nicht verfügbar. Das System solle komplett dokumentiert werden. «Die Systeme verändern sich täglich. Das Backup muss richtig kontroliert werden und erst ein echter Wiederherstellungstest mit dem Anwender garantiert Sicherheit», so Dolewski. Laut seiner Erfahrung haben Backups eine Erfolgsrate von 97 Prozent. Die 3 Prozent der Zeit ohne Backup entsprechen aber 11 Tagen pro Jahr, an denen im Falle einer Katastrophe die Daten verloren wären. Gemäss dem IBM Resiliency Panel 2011 sind 38 Prozent aller Backups nicht komplett und 12 Prozent unbrauchbar.
«Werft die Bänder weg»

Dolewski hält die Geschwindigkeit und Zuverlässigkeit von Tape-Speicher für ungeeignet im Disaster Recovery. (mro)
Die Frage nach dem geeigneten Medium sei vorallem an der Geschwindigkeit zu bemessen und somit klar: «Werft die Bänder weg; sie sind kaputt!» Magnetbänder, auch «Tapes» genannt, können weder über Geschwindigkeit noch über Verfügbarkeit mit einem Speichernetz aus Festplatten (Storage Area Network Replication) konkurrenzieren.
«Die Menschen sind das Problem» Richard Dolewski
Ein unterbruchsfreies «Active Monitoring» unterstützt die Verantwortlichen, jederzeit den Überblick zu erhalten. Mit all diesen technischen Voraussetzungen an die Strategie für Notfall-Wiederherstellung, sind ganze virtuelle Systeme portierbar und gleichzeitig an mehreren Orten einsatzbereit. Die Grundvoraussetzung für erfolgreiche Notfall-Wiederherstellung sei, die Daten in mehreren Regionen zu speichern. Für den Datenabgleich von zwei Standorten in Echtzeit sind heute bis 1200 Kilometer möglich.
Jedes Unternehmen braucht Disaster Recovery
Kurz zusammengefasst verlangt Dolewski, dass jedes Unternehmen eine Disaster-Recovery-Lösung braucht und damit nötigen Ansprüche an die Angestellten reduziert. «Disaster Recovery» müsse raus aus der gleichen Region, um gegen Katastrophen geschützt zu sein. Man müsse die Lösung für Wiederherstellung (Recovery) und Verfügbarkeit (Availability) modernisieren.
(Marco Rohner)
Disaster Recovery
(Wikipedia) – Der Begriff «Disaster Recovery» (im Deutschen auch Notfall-Wiederherstellung genannt) bezeichnet Massnahmen, die nach einem Unglücksfall in der Informationstechnik eingeleitet werden. Dazu zählt sowohl die Daten-Wiederherstellung als auch das Ersetzen nicht mehr benutzbarer Infrastruktur, Hardware und Organisation. Umfassender als Disaster Recovery ist der Begriff Business Continuity, der nicht die Wiederherstellung der IT-Dienste, sondern unterbrechungsfreie Geschäftsabläufe in den Vordergrund stellt. Bei der Beurteilung einer Disaster-Recovery-Lösung sind folgende Punkte einer Business Impact Analyse zu beachten.
Recovery Time Objective (RTO)
Wie lange darf ein Geschäftsprozess/System ausfallen? Bei der Recovery Time Objective handelt es sich um die Zeit, die vom Zeitpunkt des Schadens bis zur vollständigen Wiederherstellung der Geschäftsprozesse (Wiederherstellung von: Infrastruktur – Daten – Nacharbeitung von Daten – Wiederaufnahme der Aktivitäten) vergehen darf. Der Zeitraum kann hier von 0 Minuten (Systeme müssen sofort verfügbar sein), bis mehreren Tage (in Einzelfällen Wochen) betragen.
Recovery Point Objective (RPO)
Wie viel Datenverlust kann in Kauf genommen werden? Bei der Recovery Point Objective handelt es sich um den Zeitraum, der zwischen zwei Datensicherungen liegen darf, das heisst, wie viele Daten/Transaktionen dürfen zwischen der letzten Sicherung und dem Systemausfall höchstens verloren gehen. Wenn kein Datenverlust hinnehmbar ist, beträgt die RPO 0 Sekunden.
Dieser Textabschnitt steht unter einer eigenen Creative Commons Lizenz (BY-SA)




Neueste Artikel von Marco Rohner (alle ansehen)
- Bund beschafft freihändig 49 Mio. Franken Auftrag von Oracle - 24. November 2016
- Ubuntu und Kubuntu 16.04 LTS im Test - 21. Oktober 2016
- Labdoo.org gewinnt Lenovo Schweiz - 4. Juli 2016

